影响网站的速度是用户的网速和网站对http请求的处理,为了提升这一点我们通常都会减少http请求,比如,js和css的合并压缩、雪碧图等等。
影响网站性能最大的因素就是浏览器的重绘和重排版了,在原生js当中,我们在遇到需要操作添加DOM的时候,一般都会使用创建文档碎片(document.createDocumentFragment)的方式来减少DOM的重绘和重排版。
React 中的React Virtual DOM 和diff 的存在实则减少网站的性能消耗,但是对于性能优化的问题,我们往往会基于一个不信任的态度,既我们需要提高React虚拟DOM 的效率。对于React来说,减少不必要的渲染是我们最普遍和最重要的优化路径。
为解决这个问题,React官方有提供一个方法,那就是PureRender。
我们从几个方面来介绍一下React的性能优化。
纯函数
纯函数是指不依赖于且不改变它作用域之外的变量状态的函数 ,纯函数有三大原则构成:
- 给定相同的输入,就一定会有相同的输出
- 运行过程中没有任何副作用
- 没有额外的状态依赖
纯函数是函数式编程的基础,完全独立于外部状态,避免了因为共享外部状态而导致bug。
第一条举例说明:
function fn(str) {
return 'welcome '+ str;
}
fn方法给定相同的输入,一定会有相同的输出,没有副作用,没有其他状态依赖。 相比较而言,js有一些内置方法就不是纯函数,比如说
Math.random()
new Date().getTime()
splice()
无论是在什么语言当中,尽可能的使用纯函数去实现程序需求都是不错的方式。因为其简介、超级独立的特点, 它容易在代码中移动、重构、重新组织,让程序更灵活,更适应将来的改变。在实现任何产品需求中,我们尽可能的将逻辑代码与业务代码分离,将状态函数和纯函数分离开来,做到低耦合都是很好的编程习惯。
第二条:过程中没有任何副作用,也就是说我们再运行的过程中,不能改变外部状态,比如说函数的参数是引用数据类型的时候,往往内部的操作会改变外部的状态。
function willChange(arr,obj) {
var newObj = arr.push(obj);
return newObj
}
var arr = ['list',1];
var obj = {title:'123'};
willChange(arr,obj);
因为是引用数据类型,因此会改变外部状态,也就产生了副作用。
解决思路就是使用Immutable的概念,将参数重新复制一份,或者说深克隆一份。这样内部操作就不会影响外部状态了。Immutable 后面会讲到。
第三条:没有额外的状态依赖,就是说不在方法内使用共享变量,因为这会给方法带来不可知因素。
React本身就是纯函数,在createElement中传入置顶的props,就会得到相应的组件,创建的过程是可预测的。
在编写React组件的过程中尽可能将组件拆分为多个子组件,对其进行更细粒度的控制。保证纯净状态们可以让方法或者组件更加专注、体积更小、更独立、更具有复用性和可预测。
PureRender
pureRender 中的pure 就是指组件满足纯函数的条件。即组件拥有相同的state和props就会得到相同的结果。
React性能优化主要就是render的优化。渲染分为初始化渲染和更新渲染。
初始化渲染没有什么可以优化的,调用所有组件的render。
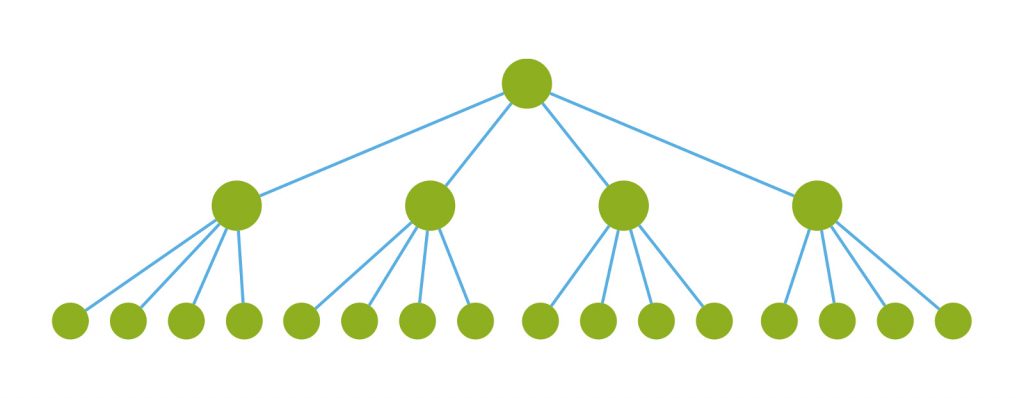
但是当我们要更新某个子组件的时候,如下图的绿色组件
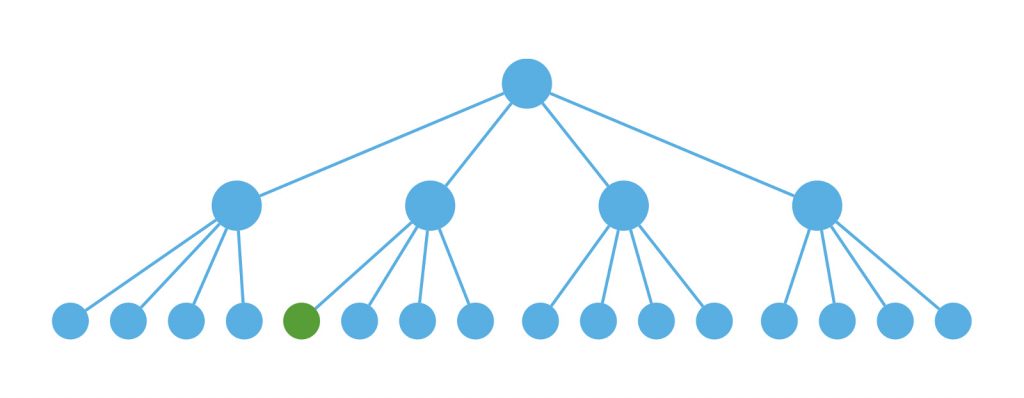
我们的理想状态是只调用关键路径上组件的render,如下图:
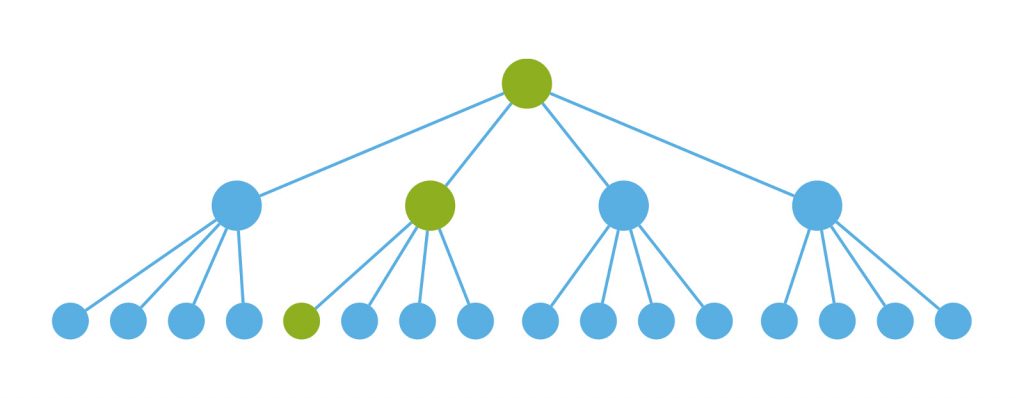
但是react的默认做法是调用所有组件的render,再对生成的虚拟DOM进行对比,如不变则不进行更新。这样的render和虚拟DOM的对比明显是在浪费,如下图(黄色表示浪费的render和虚拟DOM对比)
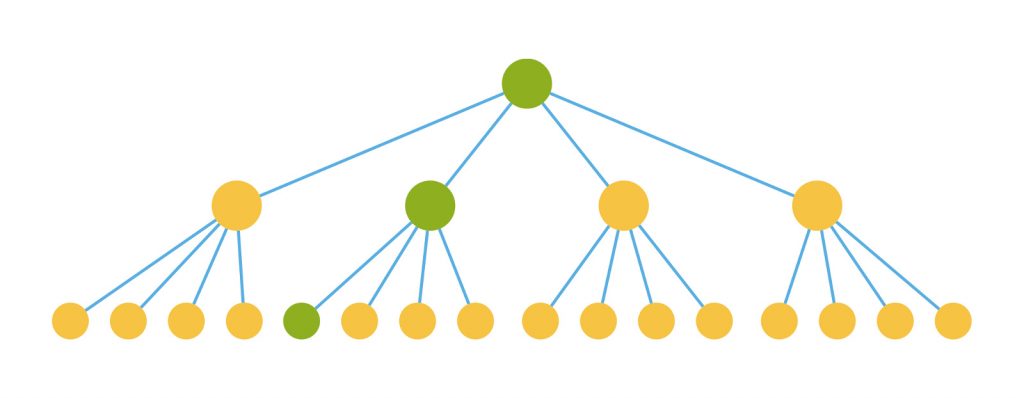
那么如何避免发生这个浪费问题呢,这就要牵出我们的shouldComponentUpdate
官方在早起就为开发者提供了名为react-addons-pure-render-mixin 的插件,原理就是重新实现了shouldComponentUpdate 方法,会将当前传入的state和props与之前的做浅比较,如果相同就返回false,render函数就不会调用。
React性能优化一般都是优化shouldComponentUpdate 方法,在理想的情况下,不考虑props和state的类型,我们要做到充分比较,只能通过深比较,但是这样是在是很昂贵。
shouldComponentUpdate(nextProps,nextState){
return isDeepEqual(this.props,nextProps)&& isDeepEqual(this.state,nextState);
}
但是如果你的state和props是基本数据类型,那么你可以欣然的使用这种方式。
import React from 'react';
import PureRenderMixin from 'react-addons-pure-render-mixin';
class Box extends React.Component {
constructor(props) {
super(props);
this.shouldComponentUpdate = PureRenderMixin.shouldComponentUpdate.bind(this);
}
render(){
return <div className={this.props.className}></div>
}
}
再此重申:PureRenderMixin内进行的仅仅是浅比较对象。如果对象包含了复杂的数据结构,深层次的差异可能会产生误判。仅用于拥有简单props和state的组件。 并且
react-addons-pure-render-mixin官方已经不再维护。
优化pureRender
拥有简单的state和props的组件应用范围不是很广,大多数组件还是需要比较复杂的props和state,这个时候PureRenderMixin 不能满足我们自身的要求,这个时候我们就需要定制 shouldComponentUpdate
如果说你的组件的state和props是引用数据类型,但是结构不是很复杂的情况下,完全可以自己写成一下类型方式
shouldComponentUpdate(object nextProps, object nextState) {
return nexprops.id !== this.props.id;
}
但是这样写的话我们的组件就会丧失部分灵活性。
优化PureRender必须先清除什么情况下会导致 其返回 true
- 直接为props设置对象和数组
我们都知道React每次重新渲染的时候,及时引用数据类型的值没有改变,他们的引用地址也会发生变化<Box style={{color:'red'}} />这样我们设置的props。每次渲染style都是一个新的对象,对于这样的操作,我们只需要提前赋值成常量就可以。再比如我们使用ant-design 或者material-ui 时 重写其样式的使用使用css in js的写法,也能避免这个问题
<Box style={this.styles.box} />到这里我们可始终让对象或者数组保持在内存找那个就可以增加命中率,但是保持对象的引用不符合函数式编程的原则,这会给函数带来副作用。
- 设置props方法并通过事件绑定在元素上
class Box extends React.Component { constructor(props) { super(props); this.state = { value: 1 } } handClick() { this.setState({ value: 2 }) } render() { return <div onClick={this.handClick.bind(this)}></div> } }这样写每次渲染都会重新绑定handClick 方法,所以我们应该放到构造器里。
class Box extends React.Component { constructor(props) { super(props); this.state = { value: 1 }; this.handClick = this.handClick.bind(this) } handClick() { this.setState({ value: 2 }) } render() { return <div onClick={this.handClick}></div> } } - 设置子组件
对于设置了子组件的React组件,在调用shouldComponentUpdate的时候, 均返回true。 为了避免子组件的重复渲染可以使用前面介绍的react-addons-pure-render-mixin
Immutable
Immutable 实则解决了一个问题:Shared mutable state is the root of all evil(共享的可变状态是万恶之源)
我们在传递数据的时候,可以使用Immutable来进一步提高渲染性能。
在JS中,引用数据类型如果使用了引用赋值,新对象的修改也会影响到原始对象。这个会造成很大的隐患。常用做法是进行浅克隆或者深克隆。但是这样又会造成内存和cpu的浪费。
PS: 这里介绍一种深克隆的奇淫技巧,在你的对象不是很复杂,没有function和正则的情况下可以使用
var newData = JSON.parse(JSON.stringify(data));
Immutable 可以很好的解决这个问题
有人说 Immutable 可以给 React 应用带来数十倍的提升,也有人说 Immutable 的引入是近期 JavaScript 中伟大的发明,因为同期 React 太火,它的光芒被掩盖了。这些至少说明 Immutable 是很有价值的,下面我们来一探究竟。
什么是 Immutable Data
Immutable Data 就是一旦创建,就不能再被更改的数据。对 Immutable 对象的任何修改或添加删除操作都会返回一个新的 Immutable 对象。Immutable 实现的原理是 Persistent Data Structure(持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变。同时为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。请看下面动画:
Facebook 工程师 Lee Byron 花费 3 年时间打造,与 React 同期出现,但没有被默认放到 React 工具集里(React 提供了简化的 Helper)。它内部实现了一套完整的 Persistent Data Structure,还有很多易用的数据类型。像 Collection、List、Map、Set、Record、Seq。有非常全面的map、filter、groupBy、reduce``find函数式操作方法。同时 API 也尽量与 Object 或 Array 类似。
其中有 3 种最重要的数据结构说明一下:
- Map:键值对集合,对应于 Object,ES6 也有专门的 Map 对象
- List:有序可重复的列表,对应于 Array
- Set:无序且不可重复的列表
Immutable 优点
- 降低了“可变"带来的复杂度:可变(Mutable)数据耦合了 Time 和 Value 的概念,造成了数据很难被回溯。
function touchAndLog(touchFn) { let data = { key: 'value' }; touchFn(data); console.log(data.key); // 猜猜会打印什么? }在不查看
touchFn的代码的情况下,因为不确定它对data做了什么,你是不可能知道会打印什么(这不是废话吗)。但如果data是 Immutable 的呢,你可以很肯定的知道打印的是value。 - 节省内存 :Immutable.js 使用了 Structure Sharing 会尽量复用内存,甚至以前使用的对象也可以再次被复用。没有被引用的对象会被垃圾回收。
import { Map} from 'immutable'; let a = Map({ select: 'users', filter: Map({ name: 'Cam' }) }) let b = a.set('select', 'people'); a === b; // false a.get('filter') === b.get('filter'); // true上面 a 和 b 共享了没有变化的
filter节点。 - 撤销/重做,复制/粘贴,甚至时间旅行这些功能做起来都是小菜一碟 :因为每次数据都是不一样的,只要把这些数据放到一个数组里储存起来,想回退到哪里就拿出对应数据即可,很容易开发出撤销重做这种功能。
- 并发安全:传统的并发非常难做,因为要处理各种数据不一致问题,因此『聪明人』发明了各种锁来解决。但使用了 Immutable 之后,数据天生是不可变的,并发锁就不需要了。然而现在并没什么卵用,因为 JavaScript 还是单线程运行的啊。但未来可能会加入,提前解决未来的问题不也挺好吗?
- 拥抱函数式编程:Immutable 本身就是函数式编程中的概念,纯函数式编程比面向对象更适用于前端开发。因为只要输入一致,输出必然一致,这样开发的组件更易于调试和组装。
Immutable 缺点
容易和原生对象弄混淆是使用Immutable的过程中遇到的最大的问题。
虽然 Immutable.js 尽量尝试把 API 设计的原生对象类似,有的时候还是很难区别到底是 Immutable 对象还是原生对象,容易混淆操作。
Immutable 中的 Map 和 List 虽对应原生 Object 和 Array,但操作非常不同,比如你要用 map.get('key') 而不是 map.key,array.get(0) 而不是 array[0]。另外 Immutable 每次修改都会返回新对象,也很容易忘记赋值。
当使用外部库的时候,一般需要使用原生对象,也很容易忘记转换。
下面给出一些办法来避免类似问题发生:
- 使用 Flow 或 TypeScript 这类有静态类型检查的工具
- 约定变量命名规则:如所有 Immutable 类型对象以
$$开头。 - 使用
Immutable.fromJS而不是Immutable.Map或Immutable.List来创建对象,这样可以避免 Immutable 和原生对象间的混用。
Immutable.is
两个 immutable 对象可以使用 === 来比较,这样是直接比较内存地址,性能最好。但即使两个对象的值是一样的,也会返回 false:
let map1 = Immutable.Map({a:1, b:1, c:1});
let map2 = Immutable.Map({a:1, b:1, c:1});
map1 === map2; // false
为了直接比较对象的值,immutable.js 提供了 Immutable.is 来做『值比较』
Immutable.is(map1, map2); // true
Immutable.is 比较的是两个对象的 hashCode 或 valueOf(对于 JavaScript 对象)。由于 immutable 内部使用了 Trie 数据结构来存储,只要两个对象的 hashCode 相等,值就是一样的。这样的算法避免了深度遍历比较,性能非常好。
Cursor 的概念
这个 Cursor 和数据库中的游标是完全不同的概念。
由于 Immutable 数据一般嵌套非常深,为了便于访问深层数据,Cursor 提供了可以直接访问这个深层数据的引用。
import Immutable from 'immutable';
import Cursor from 'immutable/contrib/cursor';
let data = Immutable.fromJS({ a: { b: { c: 1 } } });
// 让 cursor 指向 { c: 1 }
let cursor = Cursor.from(data, ['a', 'b'], newData => {
// 当 cursor 或其子 cursor 执行 update 时调用
console.log(newData);
});
cursor.get('c'); // 1
cursor = cursor.update('c', x => x + 1);
cursor.get('c'); // 2
Immutable VS PureRender
前面已经介绍过了,React性能优化时最常用的就是shouldComponentUpdate 方法,但是他默认返回 true,即始终会执行 render() 方法,然后做 Virtual DOM 比较,并得出是否需要做真实 DOM 更新,这里往往会带来很多无必要的渲染并成为性能瓶颈。
当然我们也可以在 shouldComponentUpdate() 中使用使用 deepCopy 和 deepCompare 来避免无必要的 render(),但 深拷贝 和 深比较 一般都是非常耗性能的。
Immutable 则提供了简洁高效的判断数据是否变化的方法,只需 === 和 is 比较就能知道是否需要执行 render(),而这个操作几乎 0 成本,所以可以极大提高性能。修改后的 shouldComponentUpdate 是这样的:
import { is } from 'immutable';
shouldComponentUpdate: (nextProps = {}, nextState = {}) => {
const thisProps = this.props || {}, thisState = this.state || {};
if (Object.keys(thisProps).length !== Object.keys(nextProps).length ||
Object.keys(thisState).length !== Object.keys(nextState).length) {
return true;
}
for (const key in nextProps) {
if (!is(thisProps[key], nextProps[key])) {
return true;
}
}
for (const key in nextState) {
if (thisState[key] !== nextState[key] || !is(thisState[key], nextState[key])) {
return true;
}
}
return false;
}
注意:React 中规定
state和props只能是一个普通对象,所以比较时要比较对象的key
使用 Immutable 后,如下图,当红色节点的 state 变化后,不会再渲染树中的所有节点,而是只渲染图中绿色的部分:
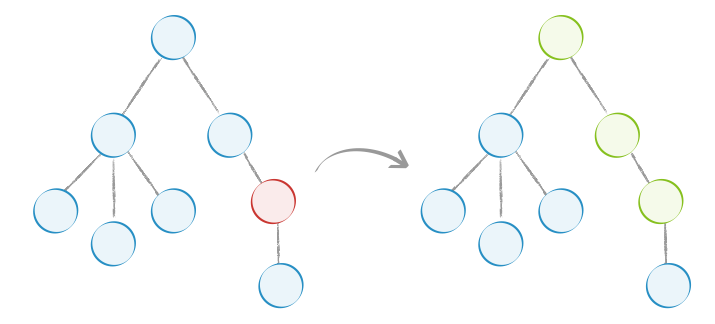
Immutable和setState
React 建议把 this.state 当作 不可变 的,因此修改前需要做一个 深拷贝
import "_" from "lodash"
class Box extends React.Component {
constructor(props) {
super(props);
this.state = {
data: {time:0}
};
}
handAdd() {
let _data = _.cloneDeep(this.state.data);
_data.time = _data.time+1;
this.setState({
data:_data
});
// 如果上面不做 cloneDeep,下面打印的结果会是已经加 1 后的值。
console.log(this.state.data.time)
}
}
使用 Immutable 后:
class Box extends React.Component {
constructor(props) {
super(props);
this.state = {
data: Map({time:0})
};
}
handAdd() {
this.setState(({data}) => ({
data: data.update('times', v => v + 1) })
});
// 这时的 time 并不会改变
console.log(this.state.data.get('time'));
}
}
Immutable 可以给应用代打极大的性能提升,但是否使用还得看项目情况,由于入侵性较强,新项目引入比较容易,老项目迁移需要谨慎的评估迁移成本,对于一些提供给外部使用的公共组件,最好不要把Immutable对象直接暴露在对外的接口中。
与 Flux 搭配使用
由于 Flux 并没有限定 Store 中数据的类型,使用 Immutable 非常简单。
现在是实现一个类似带有添加和撤销功能的 Store:
import { Map, OrderedMap } from 'immutable';
let todos = OrderedMap();
let history = []; // 普通数组,存放每次操作后产生的数据
let TodoStore = createStore({
getAll() { return todos; }
});
Dispatcher.register(action => {
if (action.actionType === 'create') {
let id = createGUID();
history.push(todos); // 记录当前操作前的数据,便于撤销
todos = todos.set(id, Map({
id: id,
complete: false,
text: action.text.trim()
}));
TodoStore.emitChange();
} else if (action.actionType === 'undo') {
// 这里是撤销功能实现,
// 只需从 history 数组中取前一次 todos 即可
if (history.length > 0) {
todos = history.pop();
}
TodoStore.emitChange();
}
});
与 Redux 搭配使用
Redux 是目前流行的 Flux 衍生库。它简化了 Flux 中多个 Store 的概念,只有一个 Store,数据操作通过 Reducer 中实现;同时它提供更简洁和清晰的单向数据流(View -> Action -> Middleware -> Reducer),也更易于开发同构应用。目前已经在我们项目中大规模使用。
由于 Redux 中内置的 combineReducers 和 reducer 中的 initialState 都为原生的 Object 对象,所以不能和 Immutable 原生搭配使用。
幸运的是,Redux 并不排斥使用 Immutable,可以自己重写 combineReducers 或使用 redux-immutablejs来提供支持。
key
在写动态组件的时候,如果没有给动态组件添加key,则会报出一个警告:
Each child in an array or iterator should have a unique "key" prop. Check the render method of....
这个警告指的是,如果每一个子组件是一个数组或者迭代器的话,那么必须有一个唯一的key。
比如说一份列表需要循环生成组件的时候,需要为组件添加一个key。经常会出现这种情况
const items = this.state.items.map((item, i) => (
<div key={i}>
{item.text}
</div>
));
我们把key设成了序号,这么做的确不会报警告了,但是这是非常低效的做法,我们在生产环境中经常会犯这种的错误,我们要知道 这个key 是每次用来 虚拟DOM diff使用的,使用列表的序号来更新的问题是它没有和列表项唯一信息相匹配。相当于一个随机键,那么不论有没有相同的项。更新都会重新渲染。
正确的做法是:
const items = this.state.items.map((item, i) => (
<div key={item.id}>
{item.text}
</div>
));
当key相同时,React会怎么渲染呢?答案就是只渲染第一个相同的key的项,并且会抱一个警告:
Warning: flattenChildren(...): Encountered two children with the same key, `1`. Child keys must be unique; when two children share a key, only the first child will be used.
因此,对于key有一个原则,那就是独一无二,且能不用随机数或者序号就不要用,除非列表内容也并不是唯一的表示,且没有可以相匹配的属性。
React.addons.Perf
做了这么多工作,怎么才能量化以上所做的性能优化的效果呢?react官方提供一个插件React.addons.Perf可以帮助我们分析组件的性能,以确定是否需要优化。
通过Perf.start() 和 Perf.stop() 两个API设置开始和结束的状态来做分析,他会把各组件渲染的各个阶段时间统计出来,然后打印出一张表格。

React-addons-perf 可以打印组件渲染的各个阶段。
Perf.printInclusive(measurements):打印出所花费的整体时间。Perf.printExclusive(measurements):打印出处理 props、getInitialState、调用 componentWillMount 和 componentDidMount 等的时间,这里面不包含 mount 组件的时间。Perf.printWasted(measurements):打印出测量时段内所浪费的时间。这部分信息是分析数据中最有用的一部分了。我们可以通过这个数据找出时间被浪费在了哪儿。浪费一般出现在组件没有渲染任何东西的时候,如上文中提到的,组件在 render 出新的虚拟 DOM 和旧的虚拟 DOM 对比之后,发现不需要更新组件。最理想的情况这个的返回值是一个空数组。Perf.printOperations(measurements):打印出分析时段内发生的底层 DOM 操作。
无论是PureRender还是key 值,整个React组件的优化逻辑都是针对虚拟DOM的跟新优化,如果需要更复杂的方法,你需要深度探究一个虚拟DOM的运行原理
参考资料
https://github.com/camsong/blog/issues/3
https://yq.aliyun.com/articles/66958
http://imweb.io/topic/577512fe732b4107576230b9
《深入React技术栈》
文章评论
Immutable和setState:这一栏的程序有问题:应该是
handAdd() {
let _data = _.cloneDeep(this.state.data);
_data.time = _data.time+1;
this.setState({
data:_data
});
}
@冯朝晖 已更正,谢谢提醒!
“React每次重新渲染的时候,引用数据类型的值没有改变,他们的引用地址也会发生变化”这个怎么理解呢
@左艳 这个可以这样理解:react重新渲染的时候相当于重新new一个实例出来,这个时候实例当中的引用数据类型即使值没有改变,他们的地址也会重新指向,所以他的引用地址会发生变化